从思考到行动:自主工具功能的深度实施,要求
栏目:行业新闻 发布时间:2025-04-19 10:48
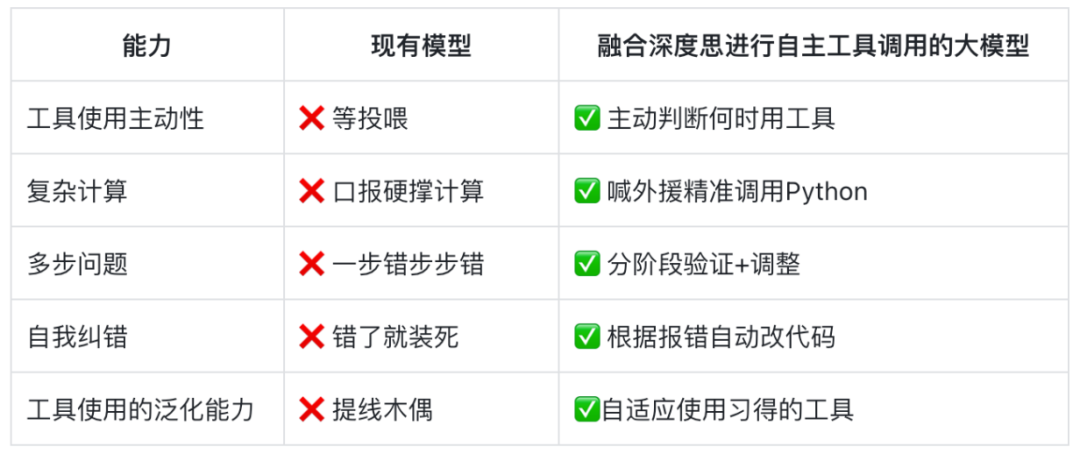 该项目由福贤教授和富丹大学Liang Jiaqing的八角兵研究员领导。医生Han Jinyi,硕士学生Li Tingyun,Xiong Chengyuan,Jiang Zishang,Wang Xinyi和其他学生参加了学生的参与。诸如GPT -4O,DeepSeek -R1之类的先进模型显示出惊人的镜头“深思熟虑”功能:了解上下文关系,破坏多步骤 - 步骤问题,甚至通过链条 - 思想进行自我验证和改进。但是,大多数主要模型仍然被误认为关键问题,在计算复杂的四个操作时犯了错误,在“将两个小数与尺寸进行比较”中犯了错误,即使是草莓中的一些“ R”也可能会失败……尽管提示了具有R1等深思熟虑功能的大型模型,但它会促使许多令牌能够正确地回答。适当的工具调用可以扩展大型模型的功能,但存在NG工具调用将大型模型限制在使用预设工具的框架中,类似于被动的“ puppet”而不是真正的活跃代理。这主要反映在以下方面:表面模仿而不是 - 深度理解:SFT仅在特定情况下学习了工具调用的表面模式,而不是真正理解边界边界,适当的情况和内部工具工作机制。它具有强大的环境,希望:基于高基的呼叫方法取决于信号的准确性和完整性。当guuse的描述不清楚或提示的设计不当时,模型无法正确选择并使用工具。工具组合功能是有限的:当需要许多工具一起解决复杂问题时,现有方法很难支持工具组合模型。 Fudan Universit符合开源项目SimpleGrpo工具。通过介绍大型模型的深刻思想,重建了大规模通话工具的范式。该技术使一个大型模型从被动执行的“ Pigpies”到具有独立决策能力的代理商实现了重大飞跃。项目的开放资源:深度集成:大型模型不仅是工具的“操纵器”,而且充分了解工具在推理过程中的功能,并了解何时以及如何使用工具更好地解决问题。动态调整:每个工具调用后,模型会根据新获得的信息自动调整其想法,继续改善解决方案,以便每次您更准确地思考。持续和灵活性:与传统的单个工具呼叫不同,自动工具调用可以使模型能够在复杂的任务中多次调用工具,并通过不断的联系获得最佳答案。创新投资组合:当工具无法完成任务时,该模型可以创新许多工具来解决更复杂的挑战。台面。通用模型的模型功能的不同性能,包括思考独立调用对工具工具的思考。如何实现大型工具的独立呼吁?我们使用强化研究算法为LLM安装一个“决策中心”,并实现两种神秘模式:解决方案1 [工作时思考]:突然编写LLM来帮助解决问题的一半思考→运行指令“相应的Snippet代码”并通过代码执行代码。实施的结果可在将大型模型识别为putum的过程中可用并重新定制。即时反馈的机制,这使该模型更改 - 然后调整随后形成的内容。此方法是与人们解决问题时一样,当他们发现程序需要提供帮助的计算任务或分析是复杂的,因此他们编写代码并操作结果。计划2 [专业人工划分]:LLM负责制定要求,直接说“我需要计算最低最低限度的38和16”,而独家代码对秒钟做出了响应!强大的团队更准确!在理解过程中,生成模型在遇到需要编程工具提供帮助的任务时清楚地描述了需求。例如,“我需要计算数据集的通常偏差”或“请帮助我实现算法的PAG-REVIEW”。对需求的描述通常用自然语言表达,清楚且易于理解。收到要求后,代码生成的特殊模型将根据描述开发相应的Python代码。该模型经过广泛训练在将语言要求转换为准确实施代码方面很好。生成模型修复了以下途径,以确保整个过程相同。lo以“在答案中”调用python命令行。当我们看到我们需要调用python程序时,在上一代过程中结合和执行并进行代码在上一代中运行。基于qwen2.5-7b,在模型中训练了QWEN2.5-7B,该模型是在模型中进行的,该命令是在命令中进行的,该命令是在命令中进行的,该命令是在数学上进行的,该命令是自动的。培训通常可以在其他问题上自动进行日:直接将ANG代码上传到草莓。计数(R)和准确的输出3!当模型称为Python程序面临更困难的问题时,我们发现扮演角色的命令线很困难。例如,当模型使用Python求解方程时,有必要导入相应的软件包。如果很难完成独立命令行的使用,并且如果一起执行许多命令行,则该模型可以轻松导致格式和代码编写错误。因此,我们试图让模型编写整个Python程序本身。主要模型:QWEN2.5-数学-7B-基础算法:增强++•数据集:MATH LEVEL3-5培训和培训重要参数设置:温度:0;研究率:4E -7; batch_size:32;奖励设置:如果答案包含\ boxed {},并且答案是正确的,则奖励mpala为1,否则奖励为0。培训的结果如下:解决复杂的100肘方程式借助编程来解决模型的内部操作系统:“这个问题是崩溃,看看我是否称呼Python!”该大型模型正在积极提出对通话工具进行试验细节的要求1。培训培训:在从数学,Numina,Opthoughts中过滤培训问题时,请遵循以下原则:使用QWEN2.5-7B-基础 - 基础构成了许多问题的答案,对模型和问题的模型和问题更简单的问题,这些问题更简单。 2。测试数据集:使用GSM8K问题作为原型,用超大(9至11个数字)或更复杂的值替换值(小数)。数据集的开源地址:https://huggingface.co/datasets/jinyihan/big-value-gsm3。算法:GRPO4。培训技巧:奖励设置:我们专注于格式的奖励和处罚,因此我们可以快速确定模型培训的早期阶段,格式的准确性逐渐达到95%以上;因此模型可以专注于提高培训最后阶段的答案的准确性。课程研究:根据模型从较小到小的模型调整正确答案的可能性,以防止同一组中GRPO标记的均匀性:在训练过程中,直接拍摄具有相同分数的样品。 5。模型选择:生成模型:QWEN2.5-7B-指令代码的模型:QWEN2.5-7B-教授该模型的实验 - 重复请求的结果,并几次调用该工具。过去:被计算出Mastubborn,今天被迫结合答案:经过思考,积极使用工具来解决其他有趣的观测观察结果:该模型可能会进一步反映代码集成的结果。当模型编写的Python代码存在汇编错误时,没有输出或运行时间:以前:发生错误后,所有后续内容都有错误。今天:该模型将继续根据错误告知来调整方法ation。通常通常可以在看不见的活动中独立调用该工具的能力。新:在调整了特定字段之后,它将不会转向隐形活动。掌握工具后,您可以轻松地使用CASE1:KNIGHT KNAVE(LOGIC -RL)案例2:倒计时以解锁新功能,并使用Python验证答案的准确性。总而言之,我们探索了两种方法来结合大型模型增强大型模型的自动工具呼叫能力的深刻能力,包括让大型模型在思考时思考和行动,并允许大型模型暗示需要调用工具。我们发现,通过研究加强的练习方式,在工作和专业人工划分的过程中进行思考,都可以在生成过程中使用灵活和自主工具进行大型呼叫工具,并在生成过程中使用自主工具工具,将工具调用结果无缝整合到后续推理和决策制定工具过程中。更重要的是,能够将此工具称为该工具的能力显示出强大的一般通用,并且可以成功地应用于完全看不见的工作情况,显示出惊人的光谱潜力。这项研究的结果为参考和技术基础提供了重要的价值,用于将来大型模型的深层思考能力的实际应用。我们计划在不久的将来发布相关的技术报告或论文,以详细解释和讨论这些方法,因此请保持专注。
该项目由福贤教授和富丹大学Liang Jiaqing的八角兵研究员领导。医生Han Jinyi,硕士学生Li Tingyun,Xiong Chengyuan,Jiang Zishang,Wang Xinyi和其他学生参加了学生的参与。诸如GPT -4O,DeepSeek -R1之类的先进模型显示出惊人的镜头“深思熟虑”功能:了解上下文关系,破坏多步骤 - 步骤问题,甚至通过链条 - 思想进行自我验证和改进。但是,大多数主要模型仍然被误认为关键问题,在计算复杂的四个操作时犯了错误,在“将两个小数与尺寸进行比较”中犯了错误,即使是草莓中的一些“ R”也可能会失败……尽管提示了具有R1等深思熟虑功能的大型模型,但它会促使许多令牌能够正确地回答。适当的工具调用可以扩展大型模型的功能,但存在NG工具调用将大型模型限制在使用预设工具的框架中,类似于被动的“ puppet”而不是真正的活跃代理。这主要反映在以下方面:表面模仿而不是 - 深度理解:SFT仅在特定情况下学习了工具调用的表面模式,而不是真正理解边界边界,适当的情况和内部工具工作机制。它具有强大的环境,希望:基于高基的呼叫方法取决于信号的准确性和完整性。当guuse的描述不清楚或提示的设计不当时,模型无法正确选择并使用工具。工具组合功能是有限的:当需要许多工具一起解决复杂问题时,现有方法很难支持工具组合模型。 Fudan Universit符合开源项目SimpleGrpo工具。通过介绍大型模型的深刻思想,重建了大规模通话工具的范式。该技术使一个大型模型从被动执行的“ Pigpies”到具有独立决策能力的代理商实现了重大飞跃。项目的开放资源:深度集成:大型模型不仅是工具的“操纵器”,而且充分了解工具在推理过程中的功能,并了解何时以及如何使用工具更好地解决问题。动态调整:每个工具调用后,模型会根据新获得的信息自动调整其想法,继续改善解决方案,以便每次您更准确地思考。持续和灵活性:与传统的单个工具呼叫不同,自动工具调用可以使模型能够在复杂的任务中多次调用工具,并通过不断的联系获得最佳答案。创新投资组合:当工具无法完成任务时,该模型可以创新许多工具来解决更复杂的挑战。台面。通用模型的模型功能的不同性能,包括思考独立调用对工具工具的思考。如何实现大型工具的独立呼吁?我们使用强化研究算法为LLM安装一个“决策中心”,并实现两种神秘模式:解决方案1 [工作时思考]:突然编写LLM来帮助解决问题的一半思考→运行指令“相应的Snippet代码”并通过代码执行代码。实施的结果可在将大型模型识别为putum的过程中可用并重新定制。即时反馈的机制,这使该模型更改 - 然后调整随后形成的内容。此方法是与人们解决问题时一样,当他们发现程序需要提供帮助的计算任务或分析是复杂的,因此他们编写代码并操作结果。计划2 [专业人工划分]:LLM负责制定要求,直接说“我需要计算最低最低限度的38和16”,而独家代码对秒钟做出了响应!强大的团队更准确!在理解过程中,生成模型在遇到需要编程工具提供帮助的任务时清楚地描述了需求。例如,“我需要计算数据集的通常偏差”或“请帮助我实现算法的PAG-REVIEW”。对需求的描述通常用自然语言表达,清楚且易于理解。收到要求后,代码生成的特殊模型将根据描述开发相应的Python代码。该模型经过广泛训练在将语言要求转换为准确实施代码方面很好。生成模型修复了以下途径,以确保整个过程相同。lo以“在答案中”调用python命令行。当我们看到我们需要调用python程序时,在上一代过程中结合和执行并进行代码在上一代中运行。基于qwen2.5-7b,在模型中训练了QWEN2.5-7B,该模型是在模型中进行的,该命令是在命令中进行的,该命令是在命令中进行的,该命令是在数学上进行的,该命令是自动的。培训通常可以在其他问题上自动进行日:直接将ANG代码上传到草莓。计数(R)和准确的输出3!当模型称为Python程序面临更困难的问题时,我们发现扮演角色的命令线很困难。例如,当模型使用Python求解方程时,有必要导入相应的软件包。如果很难完成独立命令行的使用,并且如果一起执行许多命令行,则该模型可以轻松导致格式和代码编写错误。因此,我们试图让模型编写整个Python程序本身。主要模型:QWEN2.5-数学-7B-基础算法:增强++•数据集:MATH LEVEL3-5培训和培训重要参数设置:温度:0;研究率:4E -7; batch_size:32;奖励设置:如果答案包含\ boxed {},并且答案是正确的,则奖励mpala为1,否则奖励为0。培训的结果如下:解决复杂的100肘方程式借助编程来解决模型的内部操作系统:“这个问题是崩溃,看看我是否称呼Python!”该大型模型正在积极提出对通话工具进行试验细节的要求1。培训培训:在从数学,Numina,Opthoughts中过滤培训问题时,请遵循以下原则:使用QWEN2.5-7B-基础 - 基础构成了许多问题的答案,对模型和问题的模型和问题更简单的问题,这些问题更简单。 2。测试数据集:使用GSM8K问题作为原型,用超大(9至11个数字)或更复杂的值替换值(小数)。数据集的开源地址:https://huggingface.co/datasets/jinyihan/big-value-gsm3。算法:GRPO4。培训技巧:奖励设置:我们专注于格式的奖励和处罚,因此我们可以快速确定模型培训的早期阶段,格式的准确性逐渐达到95%以上;因此模型可以专注于提高培训最后阶段的答案的准确性。课程研究:根据模型从较小到小的模型调整正确答案的可能性,以防止同一组中GRPO标记的均匀性:在训练过程中,直接拍摄具有相同分数的样品。 5。模型选择:生成模型:QWEN2.5-7B-指令代码的模型:QWEN2.5-7B-教授该模型的实验 - 重复请求的结果,并几次调用该工具。过去:被计算出Mastubborn,今天被迫结合答案:经过思考,积极使用工具来解决其他有趣的观测观察结果:该模型可能会进一步反映代码集成的结果。当模型编写的Python代码存在汇编错误时,没有输出或运行时间:以前:发生错误后,所有后续内容都有错误。今天:该模型将继续根据错误告知来调整方法ation。通常通常可以在看不见的活动中独立调用该工具的能力。新:在调整了特定字段之后,它将不会转向隐形活动。掌握工具后,您可以轻松地使用CASE1:KNIGHT KNAVE(LOGIC -RL)案例2:倒计时以解锁新功能,并使用Python验证答案的准确性。总而言之,我们探索了两种方法来结合大型模型增强大型模型的自动工具呼叫能力的深刻能力,包括让大型模型在思考时思考和行动,并允许大型模型暗示需要调用工具。我们发现,通过研究加强的练习方式,在工作和专业人工划分的过程中进行思考,都可以在生成过程中使用灵活和自主工具进行大型呼叫工具,并在生成过程中使用自主工具工具,将工具调用结果无缝整合到后续推理和决策制定工具过程中。更重要的是,能够将此工具称为该工具的能力显示出强大的一般通用,并且可以成功地应用于完全看不见的工作情况,显示出惊人的光谱潜力。这项研究的结果为参考和技术基础提供了重要的价值,用于将来大型模型的深层思考能力的实际应用。我们计划在不久的将来发布相关的技术报告或论文,以详细解释和讨论这些方法,因此请保持专注。